注記
完全な例コードをダウンロードするには、ここをクリックしてください。 または、Binder を使用してブラウザでこの例を実行します。
Fisherベクトル特徴エンコーディング#
Fisherベクトルは、画像の特徴エンコーディングと量子化技術であり、人気のBag-of-Visual-WordsやVLADアルゴリズムのソフトまたは確率的バージョンと見なすことができます。画像は、SIFTやORB記述子などの低レベルの画像特徴でトレーニングされたK-modeガウス混合モデルを使用して推定された視覚的ボキャブラリを使用してモデル化されます。Fisherベクトル自体は、混合重み、平均、共分散行列というパラメータに関して、ガウス混合モデル(GMM)の勾配を連結したものです。
この例では、scikit-learnの数字データセットに対してFisherベクトルを計算し、これらの表現で分類器をトレーニングします。
この例を実行するには、scikit-learnが必要であることに注意してください。
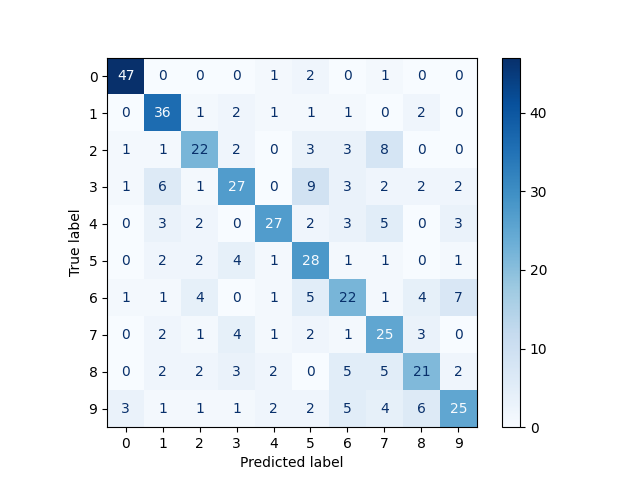
precision recall f1-score support
0 0.89 0.92 0.90 51
1 0.67 0.82 0.73 44
2 0.61 0.55 0.58 40
3 0.63 0.51 0.56 53
4 0.75 0.60 0.67 45
5 0.52 0.70 0.60 40
6 0.50 0.48 0.49 46
7 0.48 0.64 0.55 39
8 0.55 0.50 0.53 42
9 0.62 0.50 0.56 50
accuracy 0.62 450
macro avg 0.62 0.62 0.62 450
weighted avg 0.63 0.62 0.62 450
from matplotlib import pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.metrics import classification_report, ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from skimage.transform import resize
from skimage.feature import fisher_vector, ORB, learn_gmm
data = load_digits()
images = data.images
targets = data.target
# Resize images so that ORB detects interest points for all images
images = np.array([resize(image, (80, 80)) for image in images])
# Compute ORB descriptors for each image
descriptors = []
for image in images:
detector_extractor = ORB(n_keypoints=5, harris_k=0.01)
detector_extractor.detect_and_extract(image)
descriptors.append(detector_extractor.descriptors.astype('float32'))
# Split the data into training and testing subsets
train_descriptors, test_descriptors, train_targets, test_targets = train_test_split(
descriptors, targets
)
# Train a K-mode GMM
k = 16
gmm = learn_gmm(train_descriptors, n_modes=k)
# Compute the Fisher vectors
training_fvs = np.array(
[fisher_vector(descriptor_mat, gmm) for descriptor_mat in train_descriptors]
)
testing_fvs = np.array(
[fisher_vector(descriptor_mat, gmm) for descriptor_mat in test_descriptors]
)
svm = LinearSVC().fit(training_fvs, train_targets)
predictions = svm.predict(testing_fvs)
print(classification_report(test_targets, predictions))
ConfusionMatrixDisplay.from_estimator(
svm,
testing_fvs,
test_targets,
cmap=plt.cm.Blues,
)
plt.show()
スクリプトの実行総時間:(0分33.406秒)